DurIAN-SC: Duration Informed Attention Network based Singing Voice Conversion System
Abstract
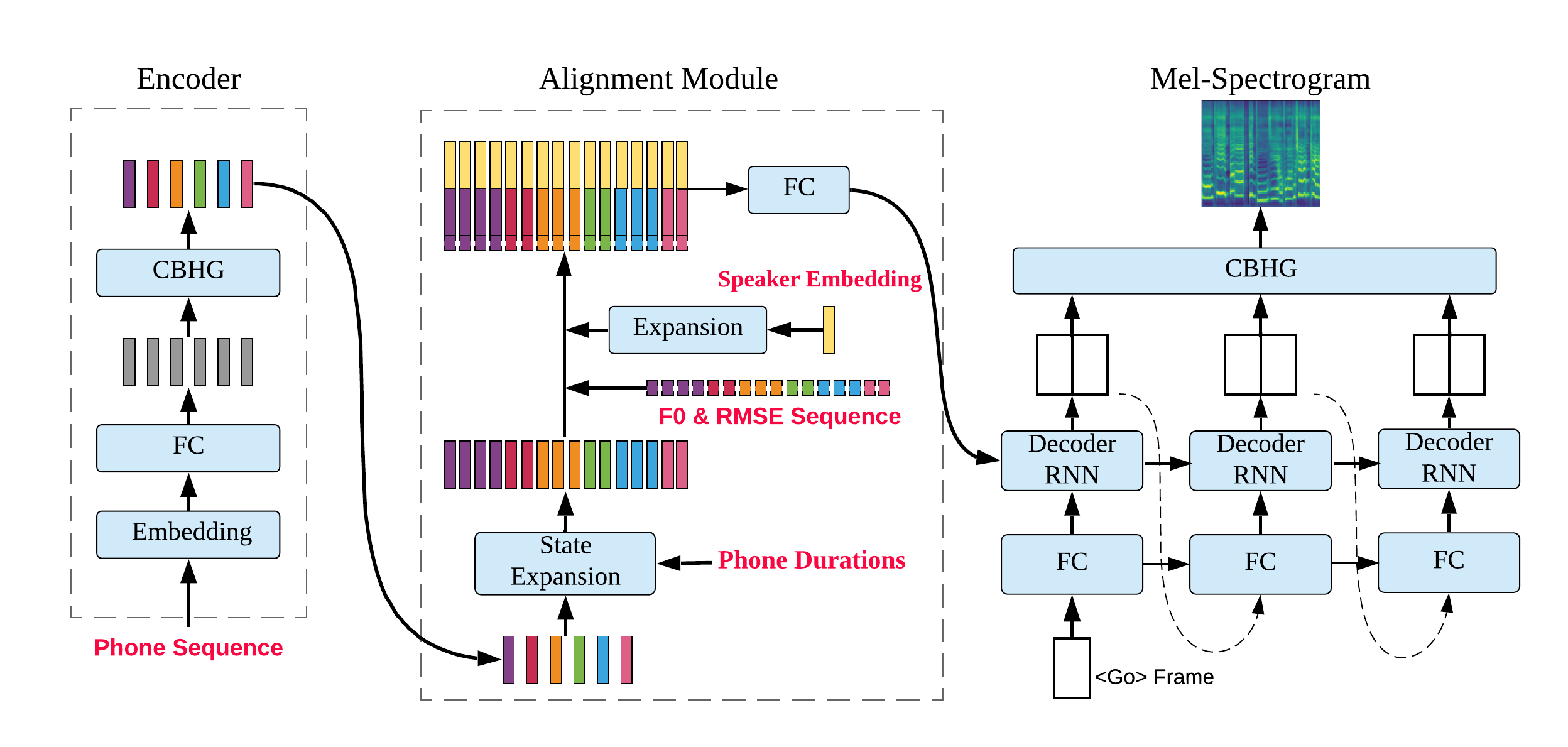
Look Up Table(LUT) based speaker embedding & D-vector based speaker embedding
* Note: All samples are in Mandrin Chinese.
* There are 6 in-set singers—3 male singers and 3 female singers, shown here.
* The “Reference Voice” is shown here for timbre similarity test, which is the target singer’s singing.
| Reference Voice | LUT Sample | D-vector Sample | |
|---|---|---|---|
| Female Singer1 | |||
| Female Singer2 | |||
| Female Singer3 | |||
| Male Singer1 | |||
| Male Singer2 | |||
| Male Singer3 |
Out-of-set test of D-vector based speaker embedding
* Note: All samples are in Mandrin Chinese.
* There are 4 out-of-set speakers—2 male speakers and 2 female speakers, shown here.
* The “Register Voice” is shown here for similarity test, which is the target speaker’s speech.
| Register Voice | D-vector Sample | |
|---|---|---|
| Female Speaker1 | ||
| Female Speaker2 | ||
| Male Speaker1 | ||
| Male Speaker2 |
Training with speech corpus
* Note: All samples are in Mandrin Chinese.
* There are 6 in-set speakers—3 male speakers and 3 female speakers, shown here.
* The “Reference Voice” is shown here for timbre similarity test, which is the target speaker’s speech.
* “Speech only” means training only with speech data, while “Speech & Singing” means training with speech data and other singers’ singing data.
| Reference Voice | Speech Only | Speechh & Singing | |
|---|---|---|---|
| Male Speaker1 | |||
| Male Speaker2 | |||
| Male Speaker3 | |||
| Female Speaker1 | |||
| Female Speaker2 | |||
| Female Speaker3 |