DurIAN : Duration Informed Attention Network For Multimodal Synthesis
Shiyin Kang, Deyi Tuo, Guangzhi Lei, Dan Su, Dong Yu
Paper link: https://arxiv.org/abs/1909.01700
Abstract
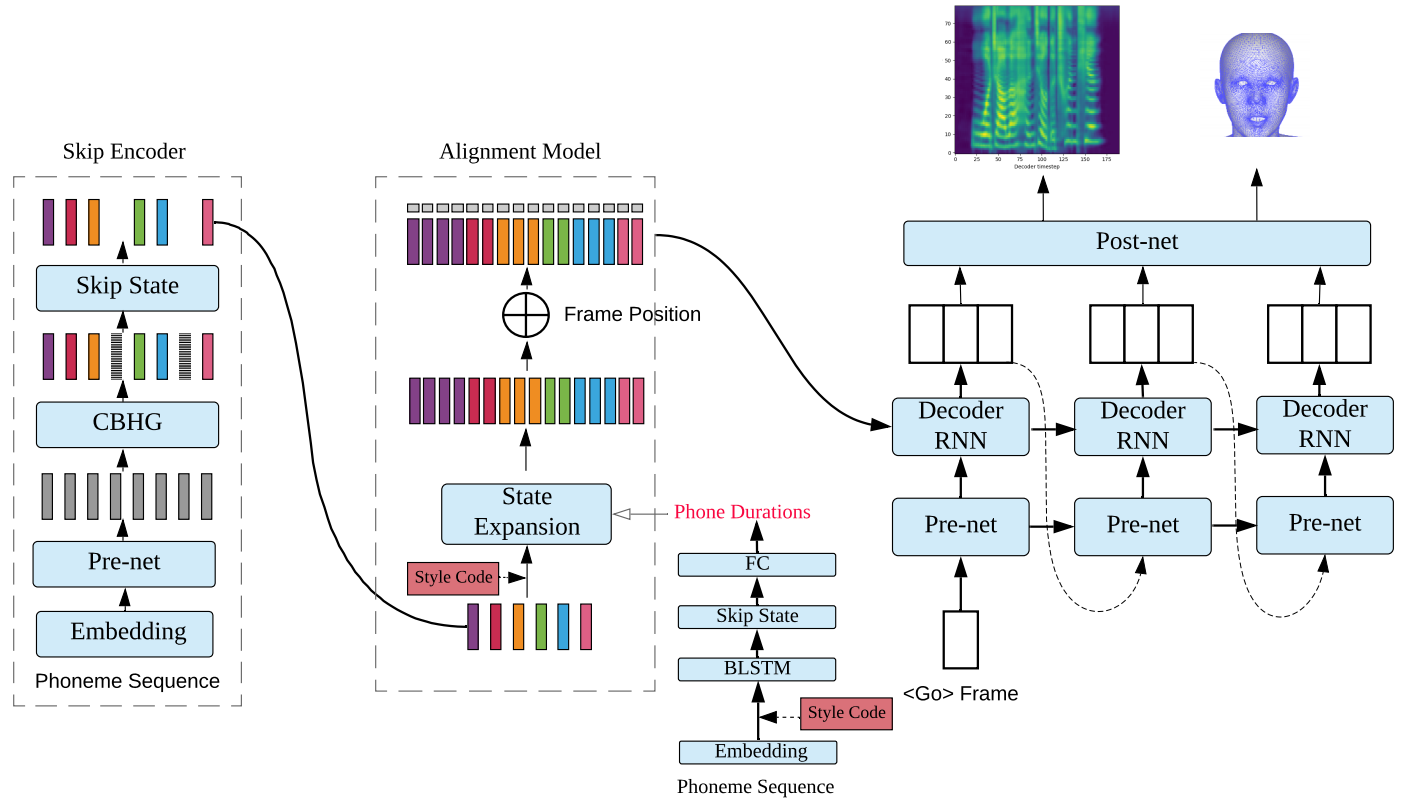
We present a generic and robust multimodal synthesis system that produces highly natural speech and facial expression simultaneously. The key component of this system is the Duration Informed Attention Network (DurIAN), an autoregressive model in which the alignments between the input text and the output acoustic features are inferred from a duration model. This is different from the end-to-end attention mechanism used, and accounts for various unavoidable artifacts, in existing end-to-end speech synthesis systems such as Tacotron. Furthermore, DurIAN can be used to generate high quality facial expression which can be synchronized with generated speech with/without parallel speech and face data. To improve the efficiency of speech generation, we also propose a multi-band parallel generation strategy on top of the WaveRNN model. The proposed Multi-band WaveRNN effectively reduces the total computational complexity from 9.8 to 3.6 GFLOPS, and is able to generate audio that is 6 times faster than real time on a single CPU core. We show that DurIAN could generate highly natural speech that is on par with current state of the art end-to-end systems, while at the same time avoid word skipping/repeating errors in those systems. Finally, a simple yet effective approach for fine-grained control of expressiveness of speech and facial expression is introduced.
Sound/Video Samples
* Note: All samples are in Mandrin Chinese.
1. Speech Synthesis Speech (Sec 5.1)
Female Synthesis Voice
| DurIAN | Tacotron-2 |
|---|---|
Male Synthesis Voice
| DurIAN | Tacotron-2 |
|---|---|
2. Fine-grained Style Control (Sec 5.3)
“现在狂铁这经济已经冠决全场啊!”
* Note: Generated with Griffin-lim vocoder.
| exciting x 0.0 | |
| exciting x 1.0 | |
| exciting x 3.0 | |
| exciting x 5.0 |
“一血九九四送出去了!”
* Note: Generated with WaveRNN vocoder.
| exciting x 0.5 | |
| exciting x 1.0 | |
| exciting x 1.5 | |
| exciting x 2.0 |
Left: Changing exciting levels during live Game Commentary generation
Right: 2006 Word Cup Jiangxiang Huang (黄健翔)commentary generation (exciting!!!)
 |
|
3. Live Game Commentary (DurIAN + WaveRNN)
Male and Female
Female
4. 3D Avatar Female Host
5. Emotional Control for talking head
Neutral (DurIAN + Griffin-lim)
Joyful (DurIAN + Griffin-lim)
Angry (DurIAN + Griffin-lim)
Sad (DurIAN + Griffin-lim)
Live commentary (DurIAN + WaveRNN)
Passionate Live commentary (DurIAN + WaveRNN)